Data Management Glossary nnn
File Data Tiering
File data tiering is a data storage management technique that automatically moves files from one storage tier to another based on usage patterns and access frequency. The goal of file data tiering is to optimize storage utilization and reduce storage costs by placing frequently used files on high-performance storage and less frequently used files (cold data storage) on lower-performance storage.
Hardware-based tiering, software-based tiering, and cloud-based tiering are three methods of file data tiering. Hardware-based tiering moves files between different types of physical storage devices, such as solid-state drives (SSDs) and hard disk drives (HDDs), within a storage array. Software-based tiering moves files between different types of virtual storage volumes, such as high-performance and low-performance storage pools. Cloud-based tiering moves files between different storage classes within a cloud-based object storage service, such as Amazon S3.
As part of a broader file data management strategy, file data tiering can help organizations improve storage utilization, reduce storage costs, and increase storage performance by automatically placing the right data in the right place at the right time. However, it’s important for organizations to carefully consider their storage requirements and choose a file tiering solution that fits their needs, as not all tiering solutions are appropriate for all environments.
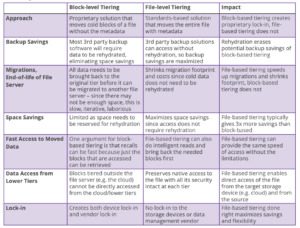
File-Level Tiering vs Block-Level Tiering
Learn the difference between storage-centric block tiering, which moves blocks that can no longer be directly accessed from their new location without vendor software (aka lock-in) and file data tiering, which is what Komprise uses to fully preserve file access at each tier by keeping the metadata and file attributes with the file—no matter where it lives. Know the difference to make the right cloud tiering choice for your data storage moves.