Data Management Glossary nnn
Data Lake
A data lake is data stored in its natural state. The term typically refers to unstructured data that is sitting on different storage environments and clouds. The data lake supports data of all types – for example, you may have videos, blogs, log files, seismic files and genomics data in a single data lake. You can think of each of your Network Attached Storage (NAS) devices as a data lake.
One big challenge with data lakes is to comb through them and find the relevant data you need. With unstructured data, you may have billions of files strewn across different data lakes, and finding data that fits specific criteria can be like finding a needle in a haystack
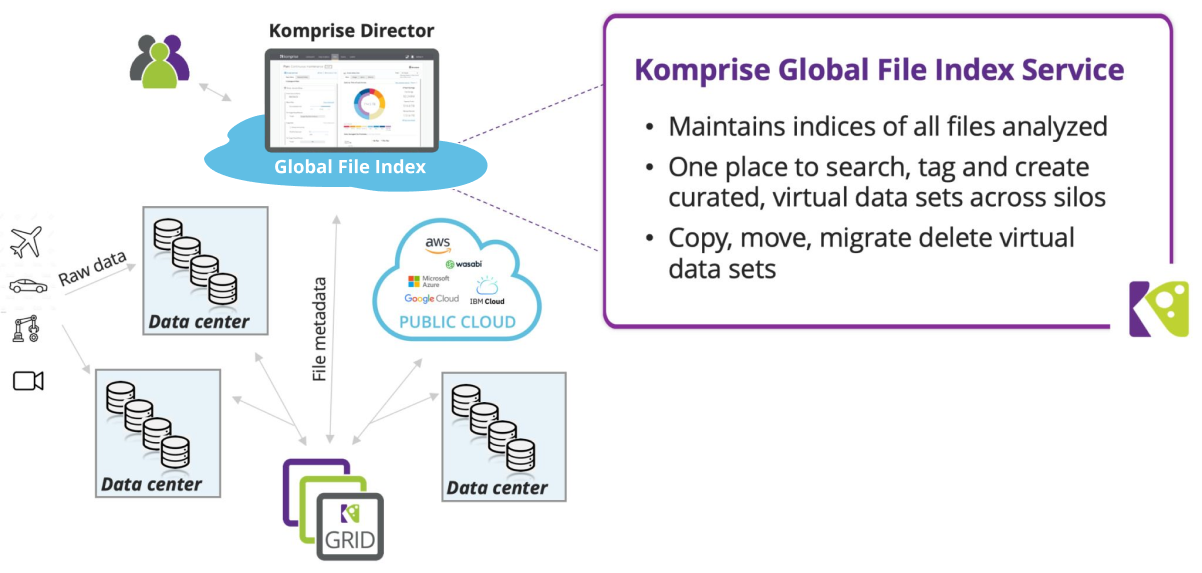
A virtual data lake is a collection of data that fits certain criteria – and as the name implies, it is virtual because the data is not moved. The data continues to reside in its original location, but the virtual data lake gives a discrete handle to manipulate that entire data set. The Komprise Global File Index can be considered to be a virtual data lake for file and object metadata.
Some key aspects of data lakes – both physical and virtual:
- Data Lakes Support a Variety of Data Formats: Data lakes are not restricted to data of any particular type.
- Data Lakes Retain All Data: Even if you do a search and find some data that does not fit your criteria, the data is not deleted from the data lake. A virtual data lake provides a discrete handle to the subset of data across different storage silos that fits specific criteria, but nothing is moved or deleted.
- Virtual Data Lakes Do Not Physically Move Data: Virtual data lakes do not physically move the data, but provide a virtual aggregation of all data that fits certain criteria. Deep Analytics can be used to specify criteria.